¶ 计算机视觉基础
¶ 视觉传感器
视觉传感器是整个机器视觉系统信息的直接来源,主要由一个或者两个图形传感器组成,有时还要配以光投射器及其他辅助设备。它的主要功能是获取足够的机器视觉系统要处理的最原始图像。图像传感器可以使用激光扫描器、线阵和面阵CCD摄像机或者TV摄像机,也可以是最新出现的数字摄像机等。视觉传感器的成像原理是基于光学成像原理。当物体被照射光线时,光线会经过透镜等光学元件聚焦在图像传感器上,形成一个二维的图像。图像传感器会将这个图像转化为数字信号,再通过信号处理器进行处理和分析。视觉传感器的精度不仅与分辨率有关,而且同被测物体的检测距离相关。被测物体距离越远,其绝对的位置精度越差。
关于视觉传感器,需要了解以下几个概念:
- 分辨率:视觉传感器的分辨率指的是其能够捕捉到的图像细节的数量。分辨率越高,传感器能够捕捉到的细节就越多,图像也就越清晰。
- 光圈和焦距:这两个参数影响了视觉传感器的成像质量。光圈决定了镜头的进光量,而焦距则决定了镜头的放大倍数和视角大小。
- 图像传感器类型:主要有CCD(电荷耦合器件)和CMOS(互补金属氧化物半导体)两种类型。它们的工作原理和性能有所不同,选择哪种类型取决于具体的应用需求。
- 噪声和动态范围:噪声指的是图像中的不希望出现的随机变化,而动态范围则是传感器能够捕捉到的最亮和最暗部分之间的比值。这两个参数都影响了图像的清晰度和质量。
- 数据传输接口:视觉传感器通常需要通过某种接口(如USB、GigE、Camera Link等)将图像数据传输到计算机或其他处理设备。了解这些接口的特性以及如何与传感器配合使用是非常重要的。
- 触发和同步:在许多应用中,可能需要精确控制视觉传感器的拍摄时机。这就需要了解有关触发和同步的概念,例如外触发、帧速率等。
- 环境和照明:视觉传感器的性能受到环境和照明条件的影响。了解如何选择合适的照明方案以及如何处理不同的环境条件对于成功应用视觉传感器至关重要。
- 视场角:视场角是指摄像机镜头能够覆盖的区域范围,通常以角度来表示。它是摄像机性能的一个重要指标,影响着摄像机的观测范围和成像质量。视场角越大,摄像机能够观测到的范围就越广,但同时可能导致图像畸变增加。
- 内外参:内参数矩阵是摄像机内部参数的集合,包括焦距、主点坐标等参数,这些参数与摄像机的物理特性有关,不会随着摄像机的移动而改变。它描述了摄像机坐标系与图像坐标系之间的关系。外参数矩阵是描述摄像机坐标系与世界坐标系之间关系的参数矩阵。它包括了旋转矩阵和平移矩阵,分别描述了世界坐标系的坐标轴相对于摄像机坐标轴的方向以及在摄像机坐标系下空间原点的位置。这些参数会随着摄像机的移动而改变。
¶ 数字图像处理知识
计算机视觉是一种利用计算机和数学方法来理解和处理图像和视频的技术。它是一种非常广泛应用的领域,可以应用于自动驾驶、人机交互、安全监控、医学图像处理、机器视觉等众多领域。计算机视觉技术主要包括图像处理、模式识别和计算机视觉算法三个方面。其中,数字图像处理是指对图像进行处理,它包括对数字图像的获取、处理、存储、传输和显示等方面的研究。数字图像处理可以应用于许多领域,如医学影像、遥感图像、计算机视觉等。在数字图像处理中,常见的操作包括图像增强、图像滤波、图像复原、图像分割、图像压缩等;模式识别是指通过对图像中的特定对象进行识别,如人脸识别、车牌识别等;计算机视觉算法是指利用数学方法来处理图像和视频,如边缘检测、目标检测和跟踪等。计算机视觉技术的发展为实现机器智能提供了重要支持,未来随着人工智能技术的不断进步,计算机视觉将有更广泛的应用和发展。
计算机视觉库是指用于计算机视觉任务的开源软件工具集合。这些库内置了各种计算机视觉算法和技术,如图像处理、图像分割、目标检测、人脸识别等,开发者可以直接使用这些算法和技术,而无需自己编写算法代码。常见的计算机视觉库包括 OpenCV、TensorFlow、PyTorch、Keras 等。其中,OpenCV 是最为流行的计算机视觉库之一,它提供了丰富的图像处理和计算机视觉算法,支持多种编程语言,如 C++、Python 等,被广泛应用于图像和视频处理领域。TensorFlow、PyTorch、Keras 等深度学习框架也提供了计算机视觉库,它们内置了深度学习算法和技术,可以用于图像分类、目标检测、人脸识别等任务。使用计算机视觉库可以大大提高开发效率和算法准确性,为计算机视觉应用开发提供了重要支持。
OpenCV(Open Source Computer Vision Library)是一个用于计算机视觉和机器学习的开源库,它提供了丰富的图像处理和计算机视觉算法,支持多种编程语言,如 C++、Python 等。OpenCV 最初是由 Intel 公司开发,现在已经成为一个跨平台的开源库,在计算机视觉领域得到广泛地应用。
OpenCV 库提供了很多常见的计算机视觉方法和算法,如图像处理、图像分割、目标检测、人脸识别、光流和结构光等。它还支持多种图像格式和视频格式,能够轻松处理常用的图像和视频数据。此外,OpenCV 还提供了丰富的工具和函数库,如图像滤波、形态学操作、特征检测和描述符、图像匹配等。这些工具和函数库可以帮助开发者快速实现各种计算机视觉任务。
OpenCV 还支持多种操作系统和平台,包括 Windows、Linux、Mac OS 等,可以在不同的硬件环境下运行。此外,OpenCV 还有许多社区提供的扩展模块,如 opencv-contrib、opencv-python 等,可以扩展 OpenCV 的功能和应用范围。
![]()
总之,OpenCV 库是一个功能强大、易于使用和跨平台的计算机视觉库,它为计算机视觉应用的开发提供了重要的支持和帮助,被广泛应用于图像和视频处理领域。
我们平时肉眼看到的图像,在机器眼中只是一段段的数字。
OpenCV 中,图像是指一个二维矩阵,其中每个元素表示一个像素。每个像素的值表示其颜色或灰度值。OpenCV 支持多种图像格式,如 PNG、JPEG、BMP 等。在 OpenCV 中,图像通常用 Mat 类来表示,Mat 类是一个矩阵类,可以表示一个图像或任何其他的多维数组。
OpenCV 中的图像可以是灰度图像或彩色图像。在灰度图像中,每个像素只有一个值,表示其灰度值。在彩色图像中,每个像素有三个值,分别表示红、绿、蓝三个颜色通道的值。OpenCV 中常用的彩色图像格式有 BGR 和 RGB,其中 BGR 表示蓝、绿、红三个颜色通道的值,而 RGB 表示红、绿、蓝三个颜色通道的值。
OpenCV 中还有一些常用的图像处理操作,如图像缩放、旋转、平移、翻转等。在图像缩放中,可以通过 resize 函数将图像的大小调整为指定大小。在图像旋转中,可以通过 getRotationMatrix2D 函数获取旋转矩阵,然后使用 warpAffine 函数进行旋转。在图像平移中,可以通过 getAffineTransform 函数获取平移矩阵,然后使用 warpAffine 函数进行平移。
¶ 简单的图像操作
接下来我们从最简单的图像生成开始
¶ 图像生成
首先,我们基于OpenCV库生成一张纯白色和一张纯黑色的图片:
import cv2
import numpy as np
# 生成一张纯白色的图片
width, height = 500, 500 # 定义图片的宽和高
white_image = np.ones((height, width, 3), dtype=np.uint8) * 255 # 生成一张纯白色的图片
black_image = np.ones((height, width, 3), dtype=np.uint8) * 0 # 生成一张纯黑色的图片
# 显示图像
cv2.imshow('Image White', white_image)
cv2.imshow('Image Black', black_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
NumPy生成图像的原理是基于数组操作。图像可以被表示为一个多维数组,其中每个元素代表像素点的颜色值。通过NumPy的数组操作,我们可以直接对图像的像素值进行操作和修改,从而生成新的图像。具体来说,NumPy提供了各种数组操作函数和数学计算函数,可以用于处理图像数据。我们可以使用NumPy创建空数组,并通过设定数组的元素值来定义图像的颜色和形状。例如,我们可以创建一个二维数组,其中每个元素代表一个像素点,然后通过设置元素的数值来改变像素点的颜色。一旦我们定义了图像数据的数组,我们可以使用NumPy的保存函数将数组保存为图像文件,如JPEG、PNG等格式。这样,我们就可以通过数组操作生成和处理图像,并实现各种图像处理任务。总的来说,NumPy生成图像的原理是利用数组操作直接对图像数据进行处理和修改,然后通过保存函数将处理后的数组保存为图像文件。这种方法提供了高效、灵活的图像处理能力,使得我们能够方便地生成、处理和操作图像数据。
注意这两行代码:
white_image = np.ones((height, width, 3), dtype=np.uint8) * 255 # 生成一张纯白色的图片
black_image = np.ones((height, width, 3), dtype=np.uint8) * 0 # 生成一张纯黑色的图片
白色图像是一个二维数组,数组的行和列分别为图像的宽和高,数组的元素为该点像素的三原色,三个通道分别为绿蓝红的颜色值。
图像的颜色是由三原色组成的,图像三原色的原理是基于加色法混合光线的原理。三原色指的是红、绿、蓝三种基本色光,它们以不同的比例混合可以产生各种颜色。当这三种色光以相同的比例混合并达到一定的强度时,就会呈现出白色光。这是因为在加色法中,光线是相加的,当所有颜色光线都加在一起时,就会得到白光。
黑色则是由于缺少光线而产生的。当没有任何色光存在时,即为黑色。在图像中,黑色通常表示像素点没有光线照射,即所有颜色通道的值都为0。
白色则相反,它表示所有颜色通道的值都为最大值。在8位图像中,每个通道的最大值为255,因此白色的RGB值为(255,255,255)。当红、绿、蓝三种色光都以最大强度混合时,就会得到白色。
因此,通过调整红、绿、蓝三原色的强度,我们可以混合出各种颜色,从而构成彩色图像。同时,通过控制光线的强度和混合比例,我们也能得到黑色和白色这两种特殊的颜色。
¶ 图像操作
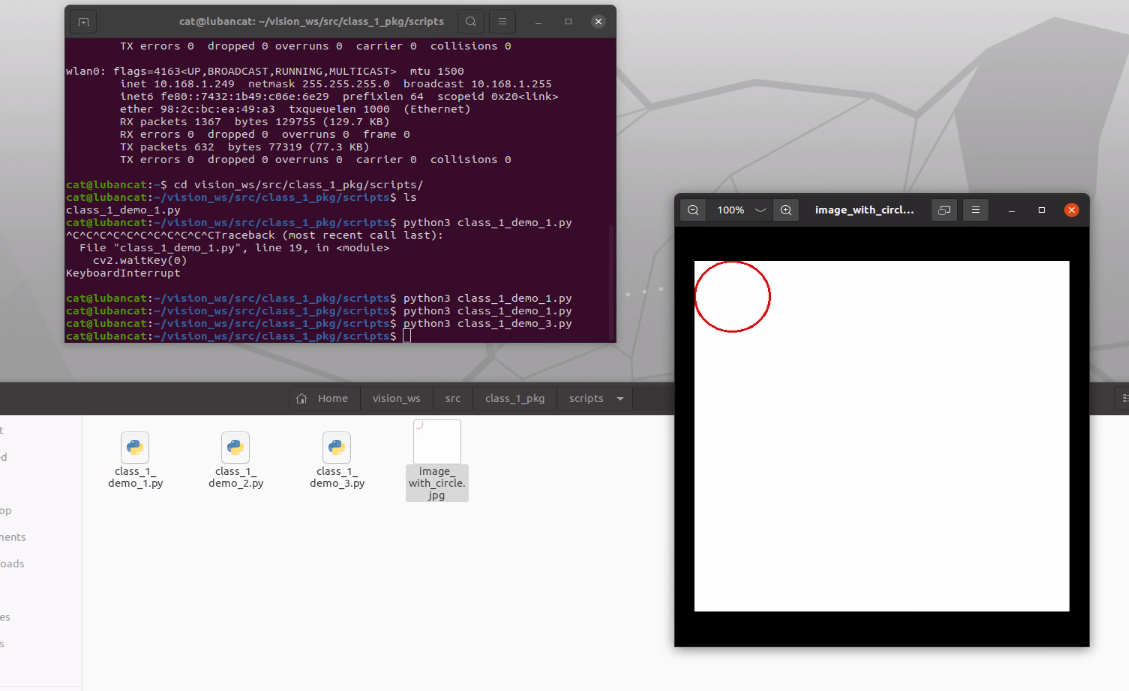
接着,我们在生成的白色图像上画一个红色圆形:
import cv2
import numpy as np
# 生成一张纯白色的图片
width, height = 500, 500 # 定义图片的宽和高
white_image = np.ones((height, width, 3), dtype=np.uint8) * 255 # 生成一张纯白色的图片
# 在图像左上方画一个红色的圆形
center_coordinates = (int(width * 0.1), int(height * 0.1)) # 圆心坐标,位于图像的左上方
radius = 50 # 圆的半径
color = (0, 0, 255) # 圆的颜色,红色
thickness = 2 # 圆的线条粗细
# 使用cv2.circle()方法在图像上画一个圆
white_image = cv2.circle(white_image, center_coordinates, radius, color, thickness)
# 显示图像
cv2.imshow('Image with Red Circle', white_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
针对图像二维数组,我们就可以使用cv2函数进行操作,执行相应的功能,例如使用cv2.circle()方法来画一个圆。
¶ 图像的保存与加载
接下来我们看看使用哪些函数可以保存和加载相应的图像,保存这张图像到本地,你可以使用cv2.imwrite()方法。加载图像可以使用cv2.imread()方法
import cv2
import numpy as np
# 生成一张纯白色的图片
width, height = 500, 500 # 定义图片的宽和高
white_image = np.ones((height, width, 3), dtype=np.uint8) * 255 # 生成一张纯白色的图片
# 在图像左上方画一个红色的圆形
center_coordinates = (int(width * 0.1), int(height * 0.1)) # 圆心坐标,位于图像的左上方
radius = 50 # 圆的半径
color = (0, 0, 255) # 圆的颜色,红色
thickness = 2 # 圆的线条粗细
# 使用cv2.circle()方法在图像上画一个圆
white_image = cv2.circle(white_image, center_coordinates, radius, color, thickness)
# 保存图像到本地
cv2.imwrite('image_with_circle.jpg', white_image)
# 加载图像
loaded_image = cv2.imread('image_with_circle.jpg')
# 显示图像
cv2.imshow('Image with Red Circle', loaded_image)
cv2.waitKey(0)
cv2.destroyAllWindows()
在这段代码中
cv2.imwrite('image_with_circle.jpg', white_image)
会将图像保存为当前目录下名为image_with_circle.jpg的文件。
然后
cv2.imread('image_with_circle.jpg')
会加载该图像文件。
¶ 获取摄像头信息
首先将摄像头通过USB连接Linux机器人主机,在终端输入 ls /dev/video观察摄像头编号:

这里我链接了很多摄像头,这里我们以0号镜头为例。
要获取摄像头信息并展示,你可以使用OpenCV库来捕获摄像头的视频流,并将每一帧图像显示出来。以下是一个简单的示例代码:
import cv2
# 打开摄像头,使用默认摄像头(索引为0)
cap = cv2.VideoCapture(0)
# 检查摄像头是否成功打开
if not cap.isOpened():
print("无法打开摄像头")
exit()
# 循环读取摄像头的每一帧图像
while True:
# 读取一帧图像
ret, frame = cap.read()
# 检查是否成功读取图像
if not ret:
print("无法获取摄像头帧")
break
# 显示图像
cv2.imshow("Camera Feed", frame)
# 按下'q'键退出循环
if cv2.waitKey(1) & 0xFF == ord('q'):
break
# 释放摄像头资源
cap.release()
# 关闭所有OpenCV窗口
cv2.destroyAllWindows()
这段代码使用
cv2.VideoCapture()
函数打开默认摄像头(索引为0),并通过循环读取每一帧图像,并使用
cv2.imshow()
函数显示每一帧图像。
在循环中使用
cv2.waitKey(1)
函数等待用户按下’q’键来退出循环。最后,释放摄像头资源并关闭所有OpenCV窗口。
这样就可以获取摄像头信息并展示了。记得在运行代码时,确保摄像头可以被正常访问。